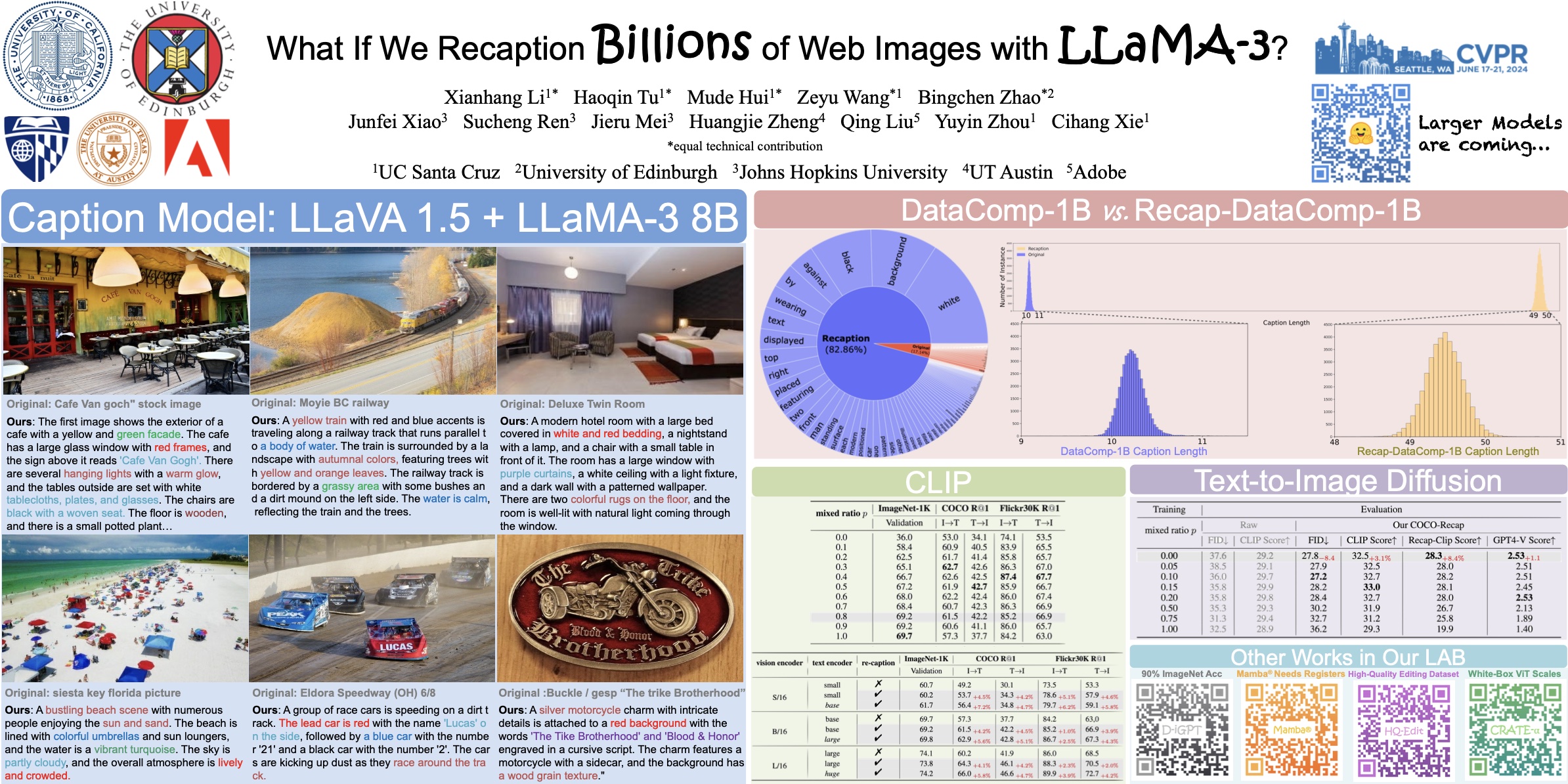
Web-crawled image-text pairs are inherently noisy. Prior studies demonstrate that semantically aligning and enriching textual descriptions of these pairs can significantly enhance model training across various vision-language tasks, particularly text-to-image generation. However, large-scale investigations in this area remain predominantly closed-source. Our paper aims to bridge this community effort, leveraging the powerful and open-sourced LLaMA-3, a GPT-4 level LLM. Our recaptioning pipeline is simple: first, we fine-tune a LLaMA-3-8B powered LLaVA-1.5 and then employ it to recaption ~1.3 billion images from the DataComp-1B dataset. Our empirical results confirm that this enhanced dataset, Recap-DataComp-1B, offers substantial benefits in training advanced vision-language models. For discriminative models like CLIP, we observe enhanced zero-shot performance in cross-modal retrieval tasks. For generative models like text-to-image Diffusion Transformers, the generated images exhibit a significant improvement in alignment with users' text instructions, especially in following complex queries. We release this dataset publicly at https://huggingface.co/datasets/UCSC-VLAA/Recap-DataComp-1B.
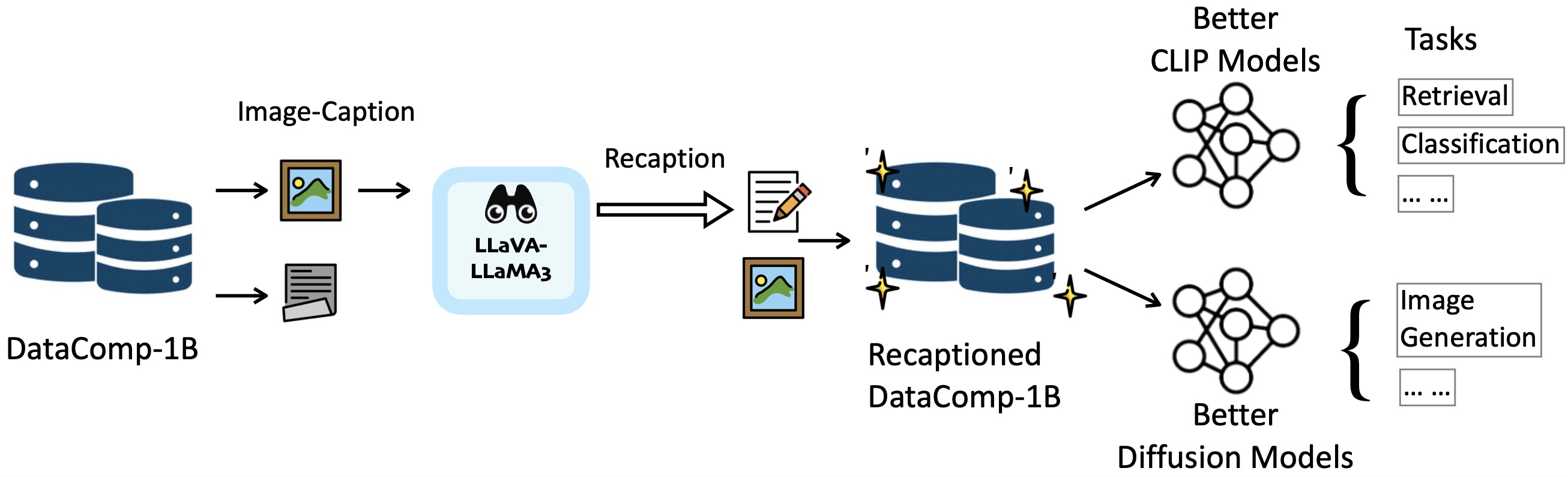
Pipeline Overview. The illustration of our recaptioning pipeline on DataComp-1B. We use LLaMA-3-powered LLaVA to reception images, which enables us to train stronger CLIP models and Text-to-Image Diffusion models.

Recaption Model Capabilities. We follow the setup of LLaVA-1.5. to build our captioner model, except that we use LLaMA-3-8B as the language decoder because of its superior performance.
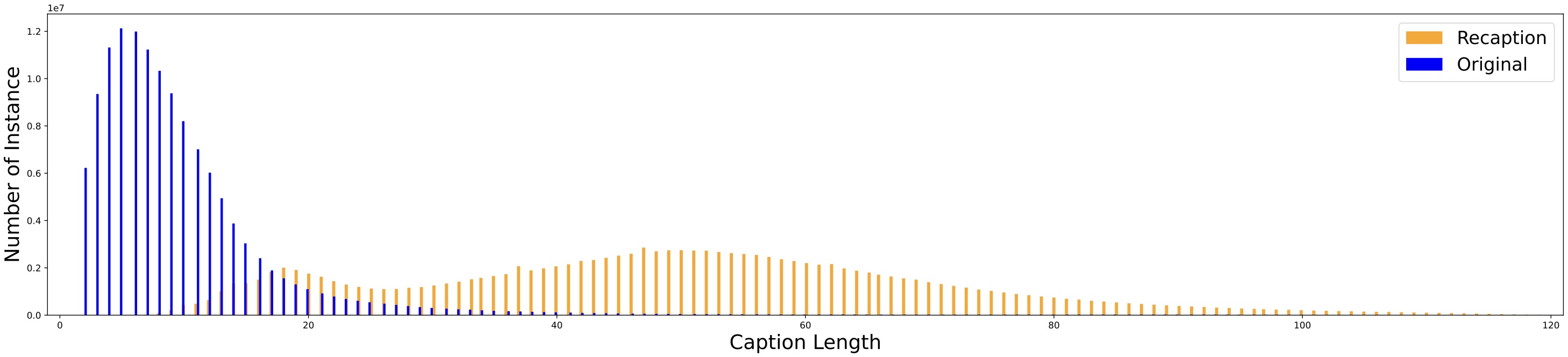
Recaption Data Statistics. Instance length distributions from ~133 million sampled examples of both the original captions and our recaptioned data in DataComp-1B.
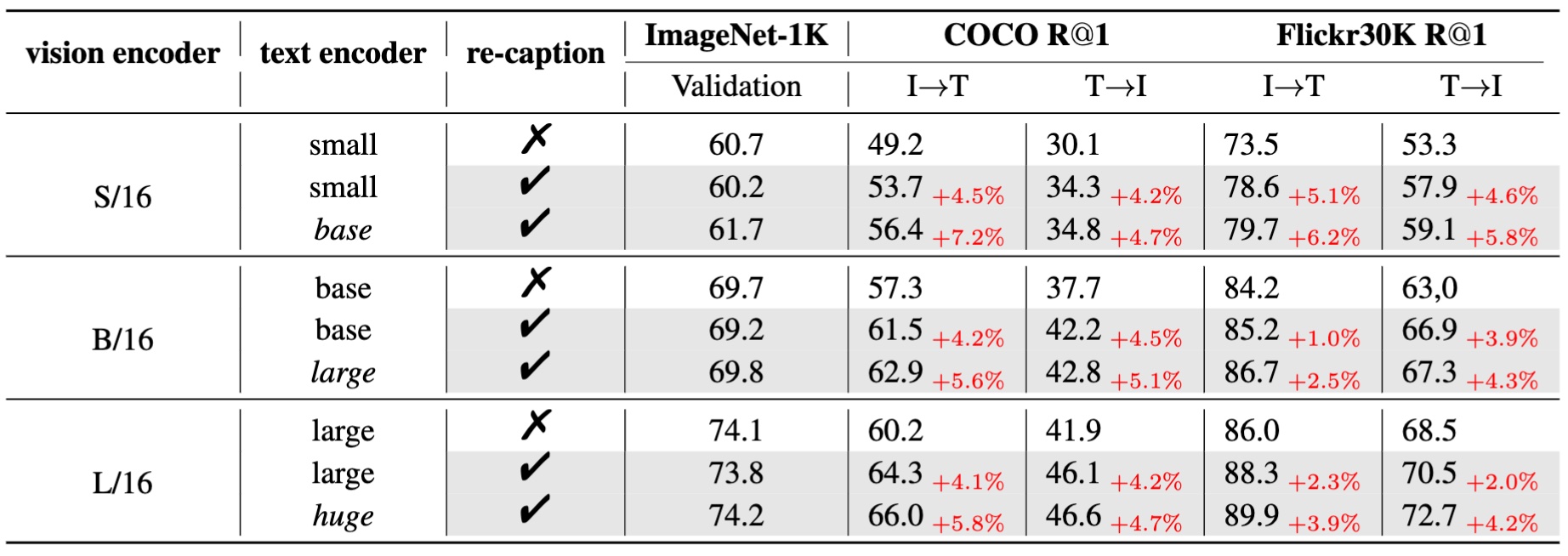
Recap-CLIP Results. We set the training mixing ratio p of recaptioned data and the original data to 0.8 for recaption-based models. We report zero-shot top-1 accuracy on ImageNet-1K and top-1 recall on COCO and Flickr30K.
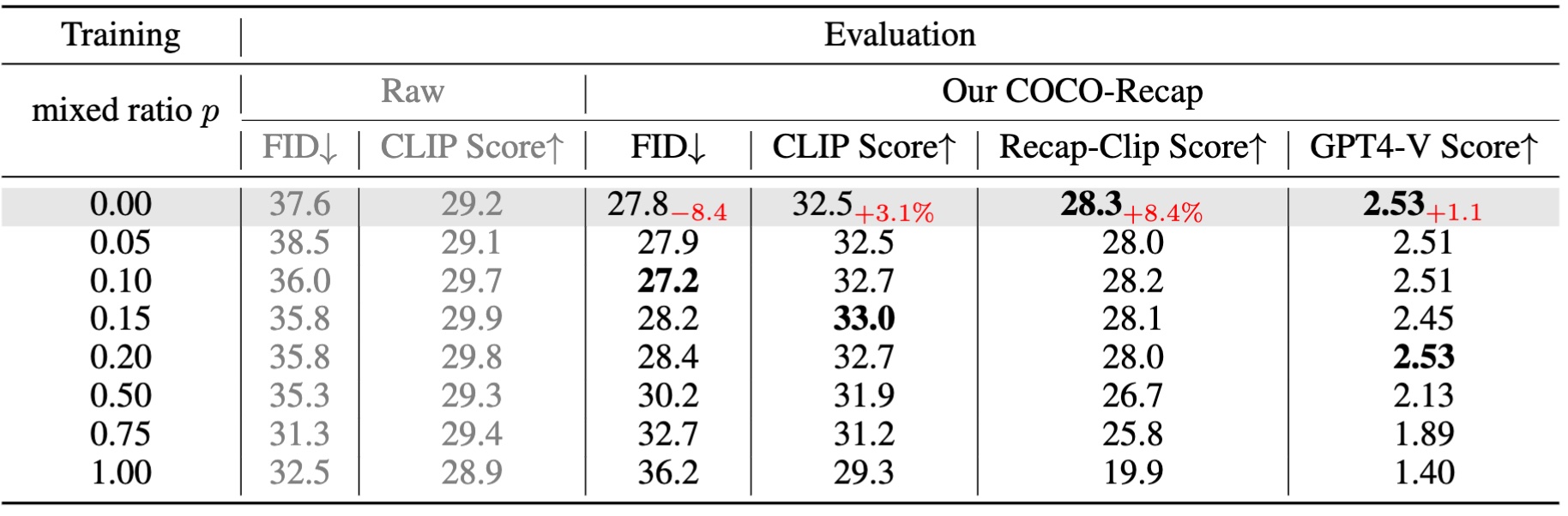
Recap-Diffusion Results. Text-to-Image evaluation on COCO-30K results of DiT-BASE/4, trained with different mix ratios on Recap-DataComp-1B. Note for GPT-4V Score, we use a subset of 3K for the evaluation.

Results Examples. Visual comparison of results from DiT-L/2 and DiT-B/4 trained with the mixed raio p=0.0.
We are pleased to announce the release of our recaptioned datasets, including Recap-DataComp-1B and Recap-COCO-30K, as well as our caption model, LLaVA-1.5-LLaMA3-8B. Stay tuned for the upcoming release of our CLIP and T2I models!
| Dataset | Num. of Sample | url |
|---|---|---|
| Recap-DataComp-1B | 1.24B | https://huggingface.co/datasets/UCSC-VLAA/Recap-DataComp-1B |
| Recap-COCO-30K | 30.5K | https://huggingface.co/datasets/UCSC-VLAA/Recap-COCO-30K |
| Model | Type | url |
|---|---|---|
| LLaVA-1.5-LLaMA3-8B | Our recaption model | https://huggingface.co/tennant/llava-llama-3-8b-hqedit |
| Recap-CLIP | CLIP | https://huggingface.co/UCSC-VLAA/ViT-L-16-HTxt-Recap-CLIP |
| Recap-DiT | Text2Image | Coming Soon... |
@article{li2024recaption,
title = {What If We Recaption Billions of Web Images with LLaMA-3?},
author = {Li, Xianhang and Tu, Haoqin and Hui, Mude and Wang, Zeyu and Zhao, Bingchen and Xiao, Junfei and Mei, Jieru and Liu, Qing and Zheng, Huangjie and Zhou, Yuyin and Xie, Cihang},
journal = {arXiv preprint arXiv:2406.08478},
year = {2024}
}



